Welcome to Pearl's official website!

Pearl - A Production-ready Reinforcement Learning AI Agent Library
Proudly brought by the Applied Reinforcement Learning team @  Meta
Meta
- v0.1 - Pearl beta-version is now released! Annoucements: Twitter Post, LinkedIn Post
- Highlighted on Meta NeurIPS 2023 Official Website: Website
- Highlighted by AI at Meta official handle on Twitter and LinkedIn: Twitter Post, LinkedIn Post.
![]()
Github Repo: Link
Our paper is ArXived at: Link
Our NeurIPS 2023 Presentation Slides is released here.
Overview
Pearl is a new production-ready Reinforcement Learning AI agent library open-sourced by the Applied Reinforcement Learning team at Meta. Furthering our efforts on open AI innovation, Pearl enables researchers and practitioners to develop Reinforcement Learning AI agents. These AI agents prioritize cumulative long-term feedback over immediate feedback and can adapt to environments with limited observability, sparse feedback, and high stochasticity. We hope that Pearl offers the community a means to build state-of-the-art Reinforcement Learning AI agents that can adapt to a wide range of complex production environments.
Getting Started
Installation
To install Pearl, you can simply clone this repo and run pip install in editable mode.
To successfully install, you need to have pip version ≥ 21.3, and setuptools version ≥ 64.
git clone https://github.com/facebookresearch/Pearl.git
cd Pearl
pip install -e .
Quick Start
To kick off a Pearl agent with a classic reinforcement learning environment, here's a quick example.
from pearl.pearl_agent import PearlAgent
from pearl.action_representation_modules.one_hot_action_representation_module import (
OneHotActionTensorRepresentationModule,
)
from pearl.policy_learners.sequential_decision_making.deep_q_learning import (
DeepQLearning,
)
from pearl.replay_buffers.sequential_decision_making.fifo_off_policy_replay_buffer import (
FIFOOffPolicyReplayBuffer,
)
from pearl.utils.instantiations.environments.gym_environment import GymEnvironment
env = GymEnvironment("CartPole-v1")
num_actions = env.action_space.n
agent = PearlAgent(
policy_learner=DeepQLearning(
state_dim=env.observation_space.shape[0],
action_space=env.action_space,
hidden_dims=[64, 64],
training_rounds=20,
action_representation_module=OneHotActionTensorRepresentationModule(
max_number_actions=num_actions
),
),
replay_buffer=FIFOOffPolicyReplayBuffer(10_000),
)
observation, action_space = env.reset()
agent.reset(observation, action_space)
done = False
while not done:
action = agent.act(exploit=False)
action_result = env.step(action)
agent.observe(action_result)
agent.learn()
done = action_result.done
Users can replace the environment with any real-world problems.
Tutorials
-
The first tutorial of Pearl focuses on recommender systems. We derived a small contrived recommender system environment using the MIND dataset (Wu et al. 2020). More details in https://github.com/facebookresearch/Pearl/tree/main/pearl/tutorials/single_item_recommender_system_example/demo.ipynb
-
The second tutorial of Pearl focuses on contextual bandit algorithms and their implementation using Pearl library. We designed a contextual bandit environment based on UCI dataset and tested the performance of neural implementations of SquareCB, LinUCB, and LinTS. More details in https://github.com/facebookresearch/Pearl/tree/main/pearl/tutorials/contextual_bandits/contextual_bandits_tutorial.ipynb
More tutorials coming in 2024.
Design and Features
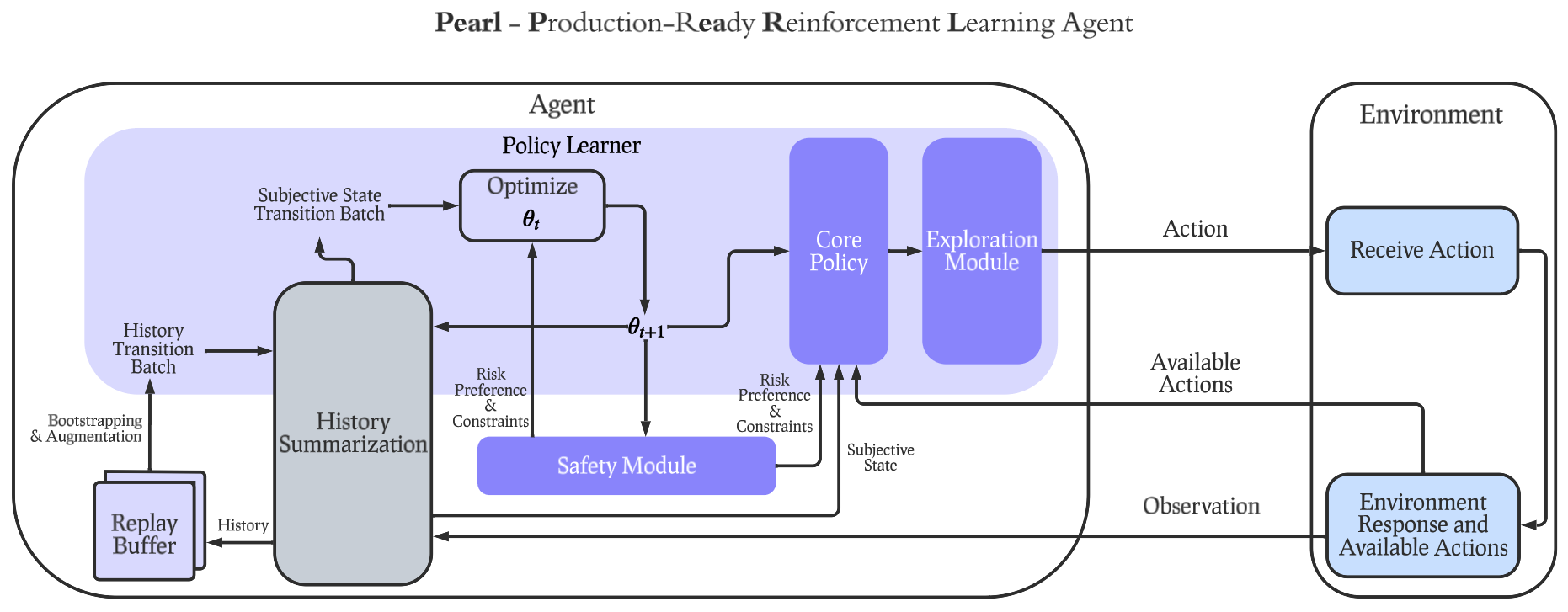 Pearl was built with a modular design so that industry practitioners or academic researchers can select any subset and flexibly combine features below to construct a Pearl agent customized for their specific use cases. Pearl offers a diverse set of unique features for production environments, including dynamic action spaces, offline learning, intelligent neural exploration, safe decision making, history summarization, and data augmentation.
Pearl was built with a modular design so that industry practitioners or academic researchers can select any subset and flexibly combine features below to construct a Pearl agent customized for their specific use cases. Pearl offers a diverse set of unique features for production environments, including dynamic action spaces, offline learning, intelligent neural exploration, safe decision making, history summarization, and data augmentation.
You can find many Pearl agent candidates with mix-and-match set of reinforcement learning features in utils/scripts/benchmark_config.py
Adoption in Real-world Applications
Pearl is in progress supporting real-world applications, including recommender systems, auction bidding system and creative selection. Each of them requires a subset of features offered by Pearl. To visualize the subset of features used by each of the applications above, see the table below.
| Pearl Features | Recommender Systems | Auction Bidding | Creative Selection |
|---|---|---|---|
| Policy Learning | ✅ | ✅ | ✅ |
| Intelligent Exploration | ✅ | ✅ | ✅ |
| Safety | ✅ | ||
| History Summarization | ✅ | ||
| Replay Buffer | ✅ | ✅ | ✅ |
| Contextual Bandit | ✅ | ||
| Offline RL | ✅ | ✅ | |
| Dynamic Action Space | ✅ | ✅ | |
| Large-scale Neural Network | ✅ |
Comparison to Other Libraries
| Pearl Features | Pearl | ReAgent (Superseded by Pearl) | RLLib | SB3 | Tianshou | Dopamine |
|---|---|---|---|---|---|---|
| Agent Modularity | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Dynamic Action Space | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Offline RL | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Intelligent Exploration | ✅ | ❌ | ❌ | ❌ | ⚪ (limited support) | ❌ |
| Contextual Bandit | ✅ | ✅ | ⚪ (only linear support) | ❌ | ❌ | ❌ |
| Safe Decision Making | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| History Summarization | ✅ | ❌ | ✅ | ❌ | ⚪ (requires modifying environment state) | ❌ |
| Data Augmented Replay Buffer | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ |
Cite Us
@article{pearl2023paper,
title = {Pearl: A Production-ready Reinforcement Learning Agent},
author = {Zheqing Zhu, Rodrigo de Salvo Braz, Jalaj Bhandari, Daniel Jiang, Yi Wan, Yonathan Efroni, Ruiyang Xu, Liyuan Wang, Hongbo Guo, Alex Nikulkov, Dmytro Korenkevych, Urun Dogan, Frank Cheng, Zheng Wu, Wanqiao Xu},
eprint = {arXiv preprint arXiv:2312.03814},
year = {2023}
}
License
Pearl is MIT licensed, as found in the LICENSE file.